We are pleased to announce that Apache Storm 0.9.2-incubating has been released and is available from the downloads page. This release includes many important fixes and improvements.
Apache Storm's Netty-based transport has been overhauled to significantly improve performance through better utilization of thread, CPU, and network resources, particularly in cases where message sizes are small. Apache Storm contributor Sean Zhong (@clockfly) deserves a great deal of credit not only for discovering, analyzing, documenting and fixing the root cause, but also for persevering through an extended review process and promptly addressing all concerns.
Those interested in the technical details and evolution of this patch can find out more in the JIRA ticket for STORM-297.
Sean also discovered and fixed an elusive bug in Apache Storm's usage of the Disruptor queue that could lead to out-of-order or lost messages.
Many thanks to Sean for contributing these important fixes.
This release also includes a number of improvements to the Apache Storm UI service. Contributor Sriharsha Chintalapani(@harshach) added a REST API to the Apache Storm UI service to expose metrics and operations in JSON format, and updated the UI to use that API.
The new REST API will make it considerably easier for other services to consume availabe cluster and topology metrics for monitoring and visualization applications. Kyle Nusbaum (@knusbaum) has already leveraged the REST API to create a topology visualization tool now included in Apache Storm UI and illustrated in the screenshot below.
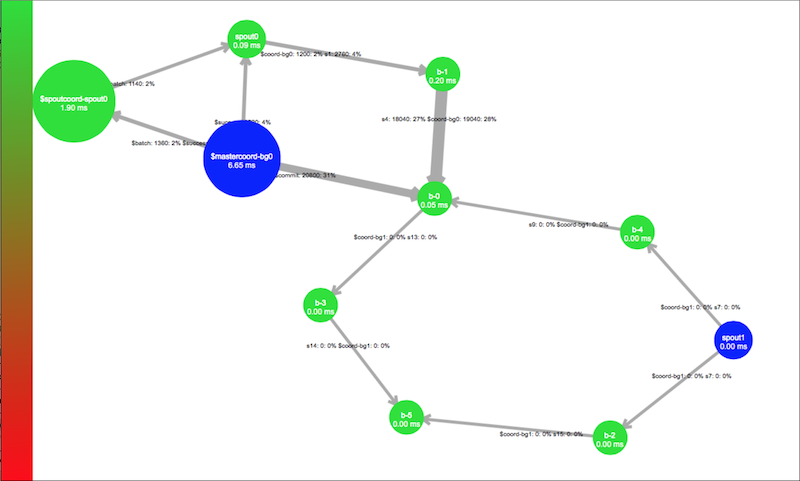
In the visualization, spout components are represented as blue, while bolts are colored between green and red depending on their associated capacity metric. The width of the lines between the components represent the flow of tuples relative to the other visible streams.
This is the first Apache Storm release to include official support for consuming data from Kafka 0.8.x. In the past, development of Kafka spouts for Apache Storm had become somewhat fragmented and finding an implementation that worked with certain versions of Apache Storm and Kafka proved burdensome for some developers. This is no longer the case, as the storm-kafka module is now part of the Apache Storm project and associated artifacts are released to official channels (Maven Central) along with Apache Storm's other components.
Thanks are due to GitHub user @wurstmeister for picking up Nathan Marz' original Kafka 0.7.x implementation, updating it to work with Kafka 0.8.x, and contributing that work back to the Apache Storm community.
The storm-kafka module can be found in the /external/ directory of the source tree and binary distributions. The external area has been set up to contain projects that while not required by Apache Storm, are often used in conjunction with Apache Storm to integrate with some other technology. Such projects also come with a maintenance committment from at least one Apache Storm committer to ensure compatibility with Apache Storm's main codebase as it evolves.
The storm-kafka dependency is available now from Maven Central at the following coordinates:
groupId: org.apache.storm
artifactId: storm-kafka
version: 0.9.2-incubating
Users, and Scala developers in particular, should note that the Kafka dependency is listed as provided. This allows users to choose a specific Scala version as described in the project README.
Similar to the external section of the codebase, we have also added an examples directory and pulled in the storm-starter project to ensure it will be maintained in lock-step with Apache Storm's main codebase.
Thank you to Apache Storm committer Michael G. Noll for his continued work in maintaining and improving the storm-starter project.
In previous versions of Apache Storm, serialization of data to and from multilang components was limited to JSON, imposing somewhat of performance penalty. Thanks to a contribution from John Gilmore (@jsgilmore) the serialization mechanism is now plugable and enables the use of more performant serialization frameworks like protocol buffers in addition to JSON.
Special thanks are due to all those who have contributed to Apache Storm -- whether through direct code contributions, documentation, bug reports, or helping other users on the mailing lists. Your efforts are much appreciated.